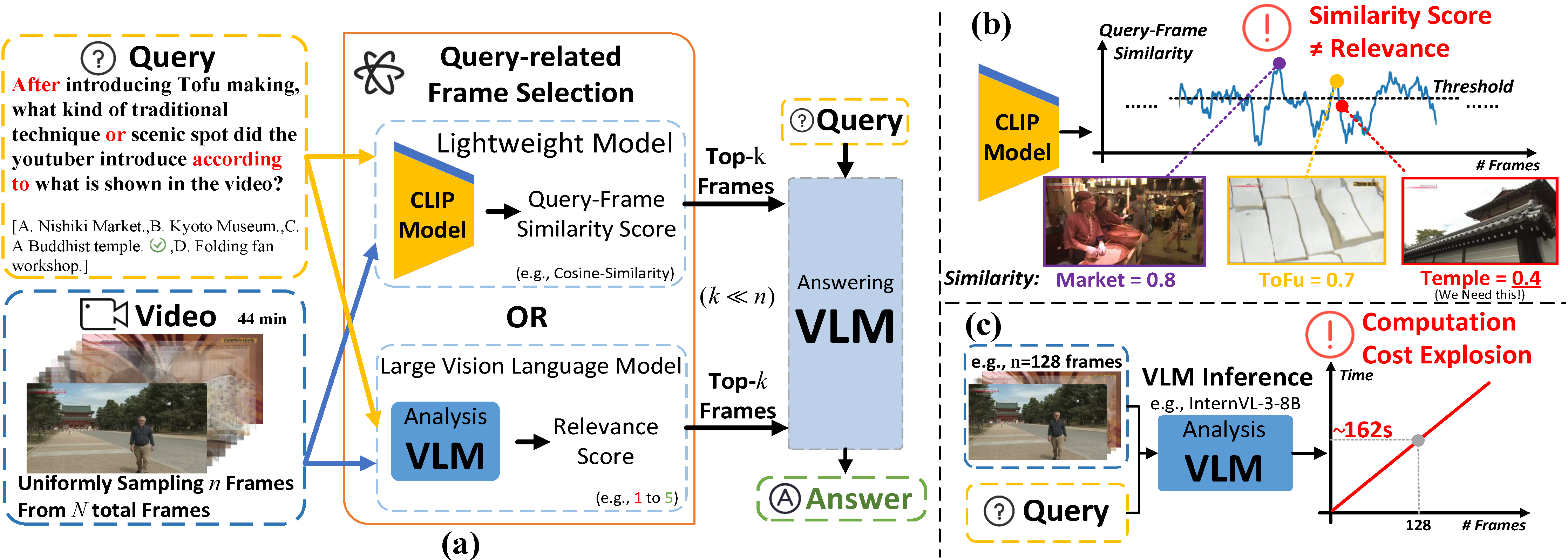
Frame Selection Process
Effectively applying Vision-Language Models (VLMs) to Video Question Answering (VideoQA) hinges on selecting a concise yet comprehensive set of frames, as processing entire videos is computationally infeasible. However, current frame selection methods face a critical trade-off: approaches relying on lightweight similarity models, such as CLIP, often fail to capture the nuances of complex queries, resulting in inaccurate similarity scores that cannot accurately reflect the authentic query-frame relevance, which further undermines frame selection.
Meanwhile, methods that leverage a VLM for deeper analysis achieve higher accuracy but incur prohibitive computational costs. To address these limitations, we propose A.I.R, a training-free approach for Adaptive, Iterative, and Reasoning-based frame selection. We leverage a powerful VLM to perform deep, semantic analysis on complex queries, and this analysis is deployed within a cost-effective iterative loop that processes only a small batch of the most promising frames at a time.
Extensive experiments on various VideoQA benchmarks demonstrate that our approach outperforms existing frame selection methods, significantly boosts the performance of the foundation VLM, and achieves substantial gains in computational efficiency over other VLM-based techniques.

Figure 2: General pipeline of A.I.R. with two stages: (1) Adaptive Initial Sampling that identifies potential 'events' based on query similarity and dynamically samples frames around them using an adaptive budget; and (2) Iterative Frame Selection that progressively refine the frame selection via four steps. The selected frames are then fed into Answering VLM.
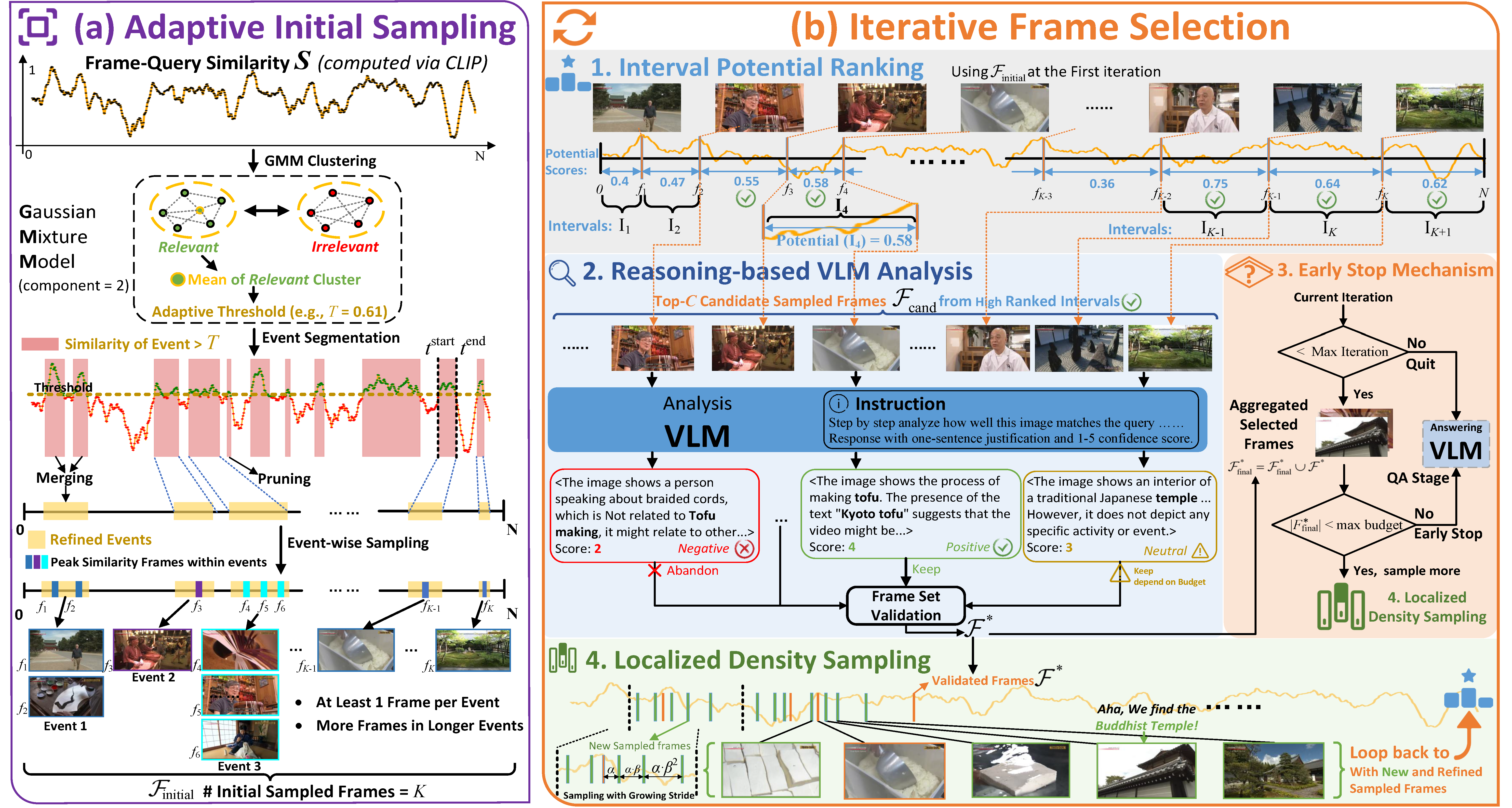
Figure 3: Two main stages in our A.I.R. (a) Adaptive Initial Sampling: A GMM-based adaptive threshold is applied to the query-frame similarity to identify potential events, and then event-wise sampling is conducted on the refined events to obtain K frames. (b) Iterative Frame Selection: In each iteration, 1) Promising candidates are selected via Interval Potential Ranking; 2) A VLM performs reasoning-based analysis to validate the best frames; 3) An Early-Stop mechanism checks if the frame budget is met; And 4) if not met, the Localized Density Sampling discovers more frames around the validated frames and feed them into the next iteration.
We evaluate A.I.R. across five challenging VideoQA benchmarks with three state-of-the-art foundation VLMs. Our method demonstrates consistent improvements across all model-benchmark combinations, validating its effectiveness as a plug-and-play solution. The performance gains are particularly pronounced on benchmarks requiring complex temporal reasoning (MLVU, NextQA), where our semantic-aware frame selection significantly outperforms uniform sampling baselines.
| Model | #Frames | Video-MME (w/o sub) |
MLVUdev | LVBval | EgoSchema | NextQA |
|---|---|---|---|---|---|---|
| QwenVL-2.5 | 32 | 60.8 | 59.3 | 58.1 | 57.6 | 74.3 |
| +A.I.R. (Ours) | ≤32 | 65.0 | 67.5 | 61.4 | 58.8 | 81.3 |
| InternVL-3 | 32 | 65.6 | 68.4 | 58.3 | 62.5 | 82.3 |
| +A.I.R. (Ours) | ≤32 | 68.2 | 74.5 | 62.8 | 63.3 | 82.6 |
| LLaVA-OneVision | 32 | 58.5 | 62.4 | 56.6 | 60.2 | 79.3 |
| +A.I.R. (Ours) | ≤32 | 61.4 | 69.3 | 60.7 | 61.4 | 81.6 |
Beyond accuracy improvements, A.I.R. achieves remarkable computational efficiency through its iterative refinement strategy. The table below breaks down the time costs for different components and compares VLM analysis time between conventional direct analysis and our method. Our Early-Stop mechanism ensures that we analyze only the necessary frames, reducing the actual analyzed frames from the theoretical maximum to achieve 50-74% time savings while maintaining superior accuracy.
| Method | #Analyzed | Time(s) |
|---|---|---|
| Component Time Cost | ||
| Baseline (Uniform 32) | - | 0.87 |
| A.I.R. (QA Stage) | - | 0.81 |
| A.I.R. (Initial Sampling) | - | 0.03 |
| A.I.R. (Frame Selection) | - | 0.18 |
| VLM Analysis Time | ||
| Direct VLM (128f) | 128 | 162.03 |
| A.I.R. (max=72) | 36.5 | 42.31 |
| Direct VLM (32f) | 32 | 42.47 |
| A.I.R. (max=32) | 20.3 | 21.92 |
| Direct VLM (16f) | 16 | 20.39 |
| A.I.R. (max=16) | 14.1 | 14.61 |
Visual comparison of frame selection results between Uniform Sampling, CLIP (Top-K), and our A.I.R. method on two example questions from different videos:
Example 1: Nahuku formation question
Example 2: Daily activities question
As shown above, A.I.R. demonstrates superior frame selection by focusing on semantically relevant frames. While Uniform Sampling includes many redundant frames and CLIP (Top-K) often selects visually similar but contextually irrelevant frames, our method precisely identifies the key moments needed to answer the questions correctly.
@article{zou2026air,
author = {Zou, Yuanhao and Jin, Shengji and Deng, Andong and Zhao, Youpeng and Wang, Jun and Chen, Chen},
title = {A.I.R.: Adaptive, Iterative, and Reasoning-based Frame Selection for Video Question Answering},
journal = {Under review at ICLR},
year = {2026},
}